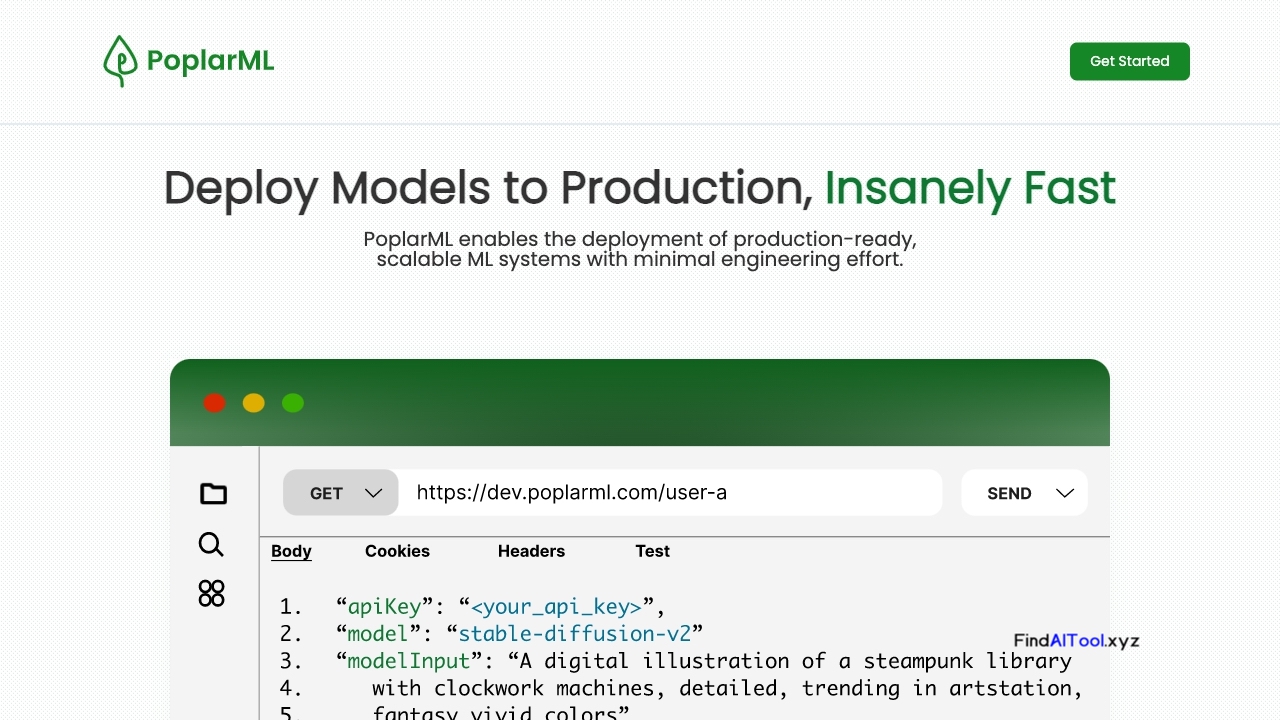
PoplarML is a cutting-edge platform designed to simplify the deployment of production-ready machine learning systems. It offers a powerful CLI tool that enables seamless deployment of ML models to a fleet of GPUs, supporting popular frameworks like TensorFlow, PyTorch, and JAX. With PoplarML, users can easily scale their ML systems and access real-time inference through a REST API endpoint.
The platform’s key features include effortless deployment, automatic scaling, and framework-agnostic support. By minimizing engineering effort, PoplarML allows data scientists and ML engineers to focus on model development rather than infrastructure management. The intuitive CLI tool streamlines the deployment process, making it accessible even to those with limited DevOps experience.
PoplarML is ideal for organizations of all sizes looking to operationalize their ML models efficiently. It caters to data science teams, ML engineers, and startups aiming to rapidly prototype and deploy AI solutions. The platform is particularly valuable for companies seeking to leverage GPU resources effectively and maintain high-performance ML systems in production environments.
By using PoplarML, users can significantly reduce time-to-market for ML-powered applications, optimize resource utilization, and ensure scalability as demand grows. The platform’s ability to handle various ML frameworks provides flexibility and future-proofing for evolving ML ecosystems. Ultimately, PoplarML empowers organizations to harness the full potential of their ML models, driving innovation and competitive advantage in today’s AI-driven landscape.