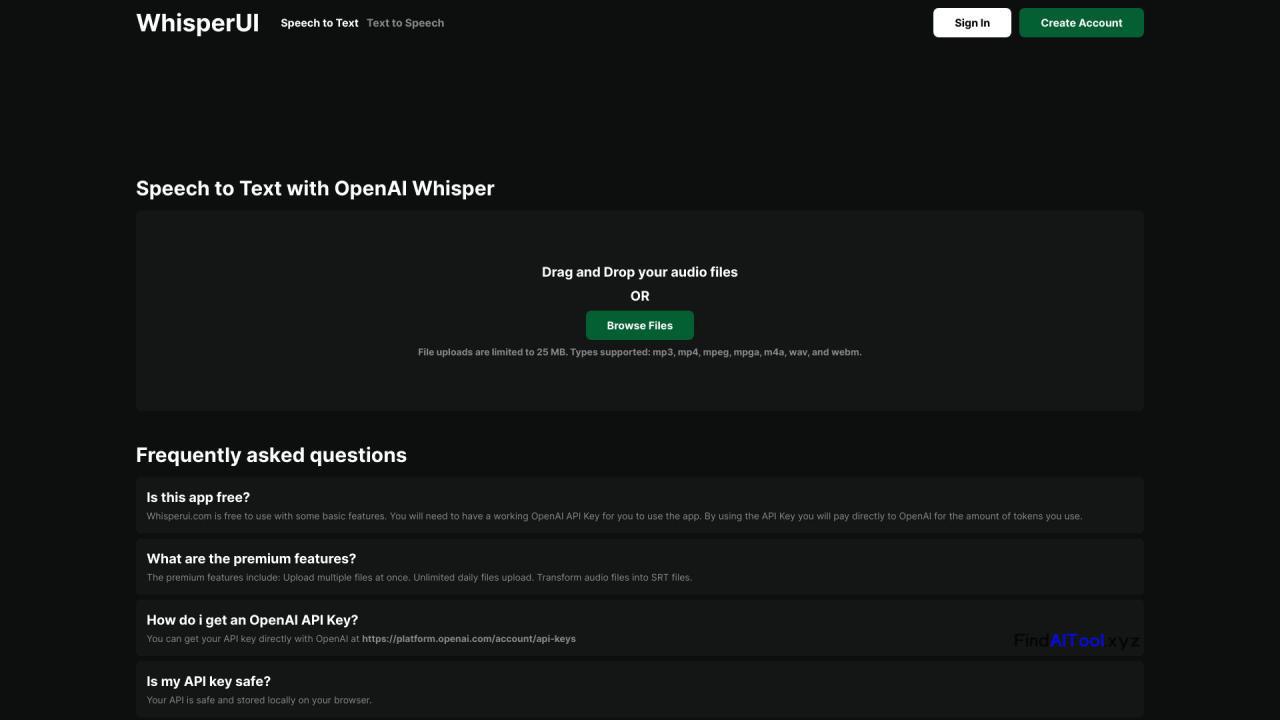
WhisperUI is an innovative text-to-speech and speech-to-text service powered by OpenAI’s Whisper API, offering affordable and efficient solutions for audio-text conversions. This versatile platform supports a wide range of audio file formats, including mp3, mp4, mpeg, mpga, m4a, wav, and webm, making it accessible for various user needs.
The software excels in converting audio files into text, transcribing spoken words, creating SRT files from audio, and even facilitating language translation. Its user-friendly interface allows for easy file uploads through drag-and-drop functionality, streamlining the conversion process.
WhisperUI is particularly beneficial for content creators, journalists, researchers, and professionals who frequently work with audio content. It’s also valuable for individuals with hearing impairments or those learning new languages. The platform’s ability to handle multiple languages makes it a powerful tool for global communication and content localization.
One of WhisperUI’s key advantages is its affordability, making advanced AI-powered audio processing accessible to a broader audience. The service ensures the security of users’ API keys and offers premium features for enhanced functionality. While the exact transcription accuracy and processing time may vary, WhisperUI strives to provide efficient and reliable results.
By simplifying the audio-to-text and text-to-audio conversion process, WhisperUI saves users significant time and effort. It enables better content accessibility, easier content repurposing, and improved workflow efficiency for professionals dealing with audio-based information. Whether for personal use or professional applications, WhisperUI offers a valuable solution for bridging the gap between spoken and written communication.